Publications
How did we get a regression model to the top of the Virtual Cell Challenge Our models
In the Virtual Cell Challenge, using only the pseudobulks from single-cell data was enough to get most of what could be learned.
A cautionary tale on biological truths Understanding data
Be very careful when adding "well-known biology" in the model as inductive bias. We learned it may backfire spectacularly.
Make multimodality work for you, not against Understanding data
Is multi-modal data the next step in understanding biology? It might be, with caveats. Thankfully, how helpful a new mode is can be tested in many ways.
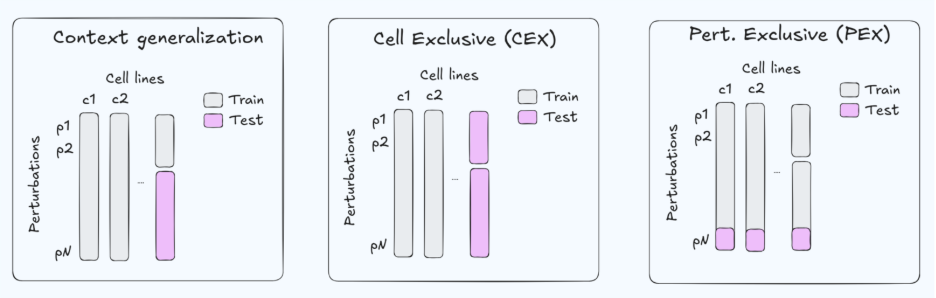
Utility of Virtual Cells Perspective
We've published a workflow on how to read and evaluate Virtual Cell papers to best understand their domain of applicability.

What can Virtual Cells do for you today? Perspective
Turns out, no matter the specific assay, today's limitations of Virtual Cells are quite uniform: they perform quite well predicting a known perturbation to unknown biosamples, they may or may not work when the perturbation itself is untrained, and they don't work at all when the entire assay is new to the model.
Masked BERT-like Pretraining of Single-cell Foundation Models Does Not Improve Virtual Cells Pretraining and foundation models
Investigating the lack of performance gains from native pretraining revealed that the way we currently train native single-cell data carries much less information than expected.
The Patient Prediction Puzzle Understanding data
Real-world patient data is inherently biased. With the correct controls applied, little distinguishing molecular information remains in TCGA data.
Benchmarking foundation cell models for post-perturbation RNA-seq prediction Pretraining and foundation models
Cell foundation models pretrained on native data add little to prediction results.
IC50 is a deep rabbit hole Understanding data
We frequently say that data harmonization is not optional in biology, it's essential. Here are some examples on how easy it is to teach the wrong idea to the machine just by feeding it unprocessed data.
Why can we predict biology? Perspective
Predicting biology is a very different problem from predicting chemistry. This is because the rules of chemistry are bottom-up and come from physics, the rules of biology are top-down and come from evolution using whatever it happened to have at its disposal.
Computational modeling of immune cell phenotypes enhances prediction of clinical anti-cancer drug response Our models
Adding predicted cytokine activity to an ensemble model may help a bit translating in vitro data to the clinic.
How to make data points worthwhile Understanding data
A theoretical treatise on efficiency gains expected from a simulation-guided lab-in-the-loop system
In defense of RNASeq Perspective
Why RNASeq could still be suitable as a good snapshot of cell state despite RNA being upstream from proteomics
The EFFECT benchmark suite: measuring cancer sensitivity prediction performance – without the bias Understanding data
A point we keep belaboring is that benchmarking is not trivial. One can easily assume that simple drug sensitivity prediction with computational models is a solved problem - it is still very much not. This benchmark we published aims to provide a better prediction of a model's usefulness in biotech applications, with robust scoring metrics and application-specific train-test splits.